Why study music: part IVa

About ten years ago, I was startled by a headline that, in essence, said if you wanted a spouse or friend who picked up your most subtle emotional cues, find a musician. Intrigued, I tracked down the research behind the article and discovered the work of Dr. Nina Kraus, Director of the Auditory Neuroscience Lab (Brainvolts) at Northwestern University.
The Lab was already known at that time for its work on the neurobiology of music and speech perception (see previous post). This particular study found that, not only were musicians better able to process the emotion in sound than non-musicians, but the ability was directly related to the number of years of experience of the musician and the age at which he/she began to study.
We know from experience that emotion isn’t found in the words themselves, but in the way the sound is communicated, the tone of voice. Mothers know, from the sound of the cry, what emotions are being conveyed by an infant or toddler, whether he is frightened, angry, or hungry.
And sarcasm is often linked to tone of voice. “Well done!” can indicate true praise, or it can be a way to ridicule someone who just made a mistake. It all depends on how you say it. If there is no tone of voice, as in e-mail or texts, it is easy for misunderstandings to occur. And while using ALL CAPS in texts is synonymous with shouting, it is considered rude and basically ineffective because it is no substitute for an actual shouting voice.
Previous research in Kraus’s lab and others had already shown that musicians had greater sensitivity to the nuances of emotion in speech than non-musicians. But this study found that musicians are not only more sensitive to the complex part of the sound that has the most to do with the emotional content (like a baby’s cry), but they de-emphasize the simpler or less emotional component of the sound. It’s not that musicians are aware of doing this with sounds other than music, but their training has made their sensitivity to the emotion in all sounds more acute.
Whatever the structure or harmonic content of a piece of music, musicians performing that piece practice to convey emotion (or not) through such means as subtle changes in timing (e.g., rubato), volume, or timbre (e.g., use of the una corda, sostenuto and damper pedals for a pianist, use of mutes for string or brass players). So it would seem to make sense that they might be more attuned to emotion in sound.
How are researchers able to measure that in the lab?
Sound enters the ear as a wave, is converted into electrical impulses, and is processed at multiple places along the auditory pathway as it travels via the brainstem to the thalamus and then to the auditory cortex where the signal is recognized or perceived as speech, music, traffic, or the doorbell.
The auditory brainstem is a kind of hub where the electrical signal coming from the inner ear is integrated with signals coming from the cerebral cortex where higher order brain processes that have been influenced by experience or learning occur, processes such as memory and attention (such as the attention that musicians give to the emotional aspects of the music they are playing). This integration shapes the ultimate signal that we perceive as sound.
Kraus and her colleagues measure neural responses at the brainstem using something called the FFR (frequency following response). Electrodes are attached to the forehead and scalp to record neural responses to speech and music. The recorded response is an objective marker of auditory function, giving the researchers information about how details of sound are transcribed in the brain and how an individual’s brain is processing sound. They have used this approach in a variety of populations, from musicians to the hearing impaired.
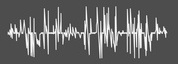
These electrical responses can be read by a computer as a waveform. The waveform provides information about pitch (frequency), timbre (harmonics), timing – the three essential components of sound – plus more.

Kraus uses an analogy of a mixing board and its ability to fine tune certain auditory signals to describe what happens in the auditory brainstem. In a sound studio, an audio engineer takes audio signals from 2 or more sources (e.g., multiple mics from different instruments or voices) and balances the relative volume and frequency of each to produce a good output signal.
At the brainstem, the incoming signal from the ear may be good, or it may be degraded due to hearing loss, autism, noisy environments, or concussion, just as an incoming signal to a mixing board may be of varying quality. The top-down signals from the cortex that meet the incoming signal at the brainstem are basically telling the brain stem what to pay attention to, augmenting some sounds, excluding irrelevant information, controlling for context, just like an audio engineer at a mixing console.
Those top-down signals will be different in each individual based on our experience. Since people who have studied music are accustomed to separating out one voice from many, at paying attention to gradations of pitch, timing and timbre, at keeping notes or rhythms in working memory, at the subtleties of expressing emotion, those circuits are enhanced in musicians and thus have a positive effect on the incoming speech signal as well. The musician’s brain is better at picking out the relevant portions of the sound, as a skilled engineer can do at a mixing board.
What is fascinating is that the recorded electrical response looks – and sounds – very much like the waveform of the original stimulus, whether music or speech. Click on the image below to see a fascinating, user-friendly three-minute presentation on the Brainvolts website discussing the lab’s approach to studying auditory processing.

What you will see in the slide presentation is that the auditory brainstem response reflects the sound stimulus so closely that when recorded and played back as a sound file, it sounds very much like the original. Hearing a short clip of the first movement of Mozart’s Eine Kleine Nachtmusik juxtaposed with the recorded brainstem response played as a sound file is astonishing. And in case you don’t recognize it, the voice clip that follows, juxtaposing the original clip with the recorded brainstem response, is from the “Mad as Hell” scene from the 1976 classic film Network.
As an aside, the Auditory Neuroscience Lab website documents their work in several areas, containing multiple short slide presentations, access to hundreds of publications going back to the 1980s, several videos of talks given by Nina Kraus, and a great deal more information. It is the most comprehensive and accessible site I have seen for any research lab.
And returning to where we started – musicians having an advantage in identifying emotion in sound. Obviously, being able to identify emotion in speech is a skill that is useful in our personal relationships, in classrooms, business settings, and in everyday encounters with people – like the friendly barista at the local coffee shop or the grumpy furnace repair man. It is also a skill that is impaired in individuals with autism and Asperger’s syndrome.
Dr. Dana Strait, the primary author in the study we’ve been discussing in this post, worked as a therapist with autistic children before becoming a neuroscientist. She suggests that musical training might promote better emotion processing in individuals with autism or Asperger’s. The Kraus Lab has found that the aspects of sound enhanced by music training are the same parts of the sound that tend to be diminished in other populations, such as in individuals with hearing disorders, autism, dyslexia, concussion, or living in poverty.
In the next post, we’re going to begin looking at Kraus’s remarkable work in school, community and clinical settings to see how she applies her research to real-life situations, and why she has become such a strong advocate for music education in schools.
2 responses to “Are musicians better at identifying emotional cues in others?”
I have witnessed autistic children who are hooked on music. they are often more willing to listen to someone if they are singing, verses just talking. Now many autistic are hooked on the computer visuals, as many young people are. I am seeing some benefits, but like all aspects of input, I think there needs to be limits of unstructured play- with games, and structured learning/ passive verses active learning.
I look forward to your next post.
Adrienne
Thanks for writing, Adrienne!